Demystifying Language Models: An Overview of LLMs


Table of contents
- Understanding LLMs
- 1. Early N-gram Models
- 2. Statistical Language Models
- 3. Neural Networks in Language Modeling
- 4. Long Short-Term Memory (LSTM) Networks
- 5. The Transformer Architecture
- Step 1: Add Special Tokens:
- Step 2: Word Tokenization:
- Step 3: Subword Tokenization:
- Step 4: Character Tokenization:
- Numerical Encoding:
- 6. GPT and BERT
- Pre-training:
- Fine-tuning:
- 7. Scaling to GPT-3:
- 8. Google’s PaLM (Pathways Language Model) and PaLM2
- Applications of LLMs
- How Vector Databases Help with Images and Search Engines
- Ethical Considerations: The Negative Effects of LLMs
- Conclusion
- References & Further Reading

Large Language Models (LLMs) have emerged as game-changers in the realm of Natural Language Processing (NLP). These powerful AI algorithms excel at understanding and generating human-like language, making them indispensable in various applications. From chatbots and virtual assistants to sentiment analysis and text summarization, LLMs have transformed the way we interact with technology. Their ability to grasp contextual relationships and nuances in language has revolutionized NLP tasks, enabling more natural and intuitive human-computer interactions.
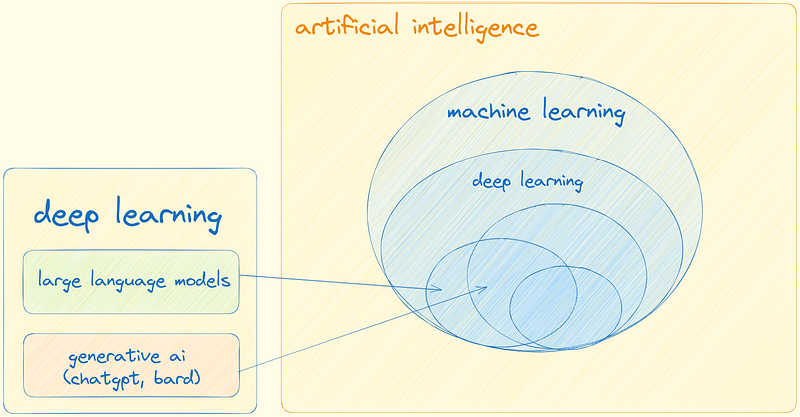
In our exploration of LLMs, we encounter the following milestones and influential models:
Development of n-gram models and Long Short-Term Memory (LSTM) networks.
Advent of the transformative Transformer architecture.
Notable models like GPT-3 and BERT setting new benchmarks in language understanding.
Image generation using Diffusion.
Understanding of Vector Databases
As we dive deeper into how LLMs work, we discover the power of the transformer model, featuring:
- Self-attention mechanism for parallel processing and capturing long-range dependencies effectively.
Tokenization and encoding are essential components that equip LLMs to comprehend raw text, converting it into numerical representations for seamless analysis.
Beyond their architecture, we address the ethical considerations surrounding LLMs:
Challenges of biased language and misinformation risks.
Ongoing research for responsible AI and ethical deployment.
With exciting possibilities on the horizon, the future of LLMs promises to unlock even more remarkable advancements in the world of AI and NLP.
Understanding LLMs
Large Language Models (LLMs) lie at the heart of modern Natural Language Processing (NLP) and play a pivotal role in enabling machines to comprehend and generate human language. These advanced AI algorithms possess the ability to process vast amounts of textual data and learn patterns, relationships, and contextual information present in language. This enables them to produce coherent and contextually relevant responses, making them invaluable in various NLP applications.
The Evolution of LLMs and How They Work?
Transformer models and BERT model: Overview — YouTube
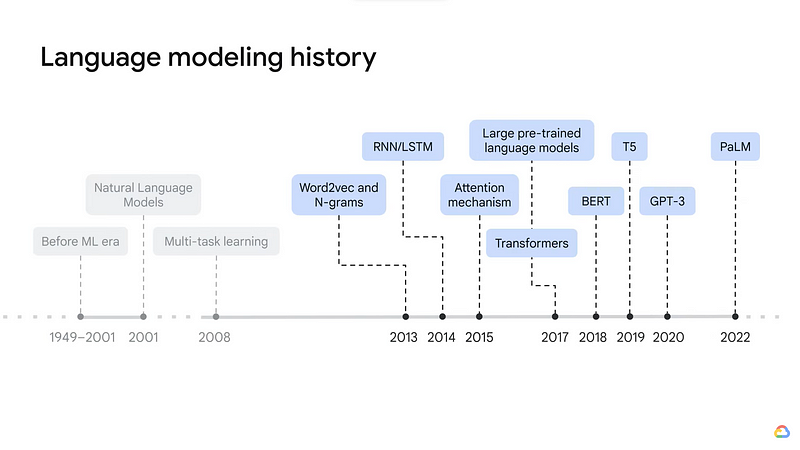
The journey of LLMs spans several decades, marked by significant breakthroughs and innovations that have propelled the field of NLP to new heights. The quest to enable machines to understand and generate human language has led to the development of increasingly sophisticated LLMs, transforming the way we interact with technology and revolutionizing AI applications. Let’s explore the key milestones in the evolution of LLMs:
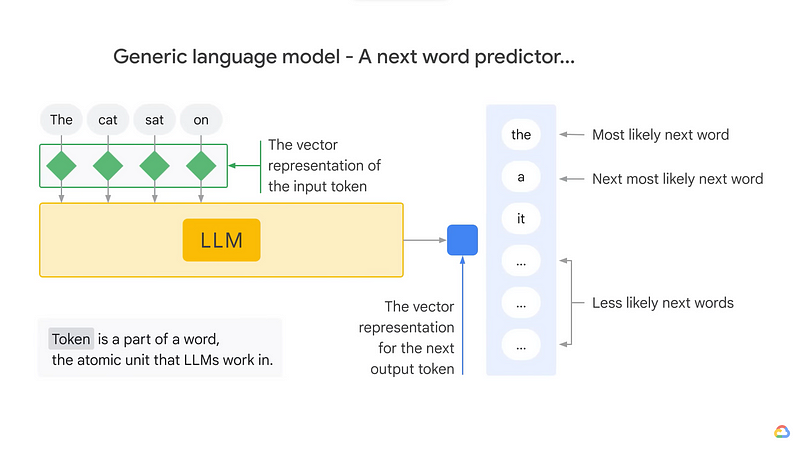
1. Early N-gram Models
Introduction to large language models — YouTube
The earliest attempts at language modeling date back to the mid-20th century with the introduction of n-gram models. These models predict the next word in a sequence based on the probabilities of preceding n-1 words. While simple, n-gram models laid the foundation for language modeling, providing insights into word co-occurrence patterns.
2. Statistical Language Models
In the 1980s and 1990s, statistical language models emerged, incorporating probabilistic approaches to language processing. Models like Hidden Markov Models (HMMs) and Maximum Entropy Models brought more sophistication to language modeling, utilizing large corpora to estimate word probabilities and improve text generation.
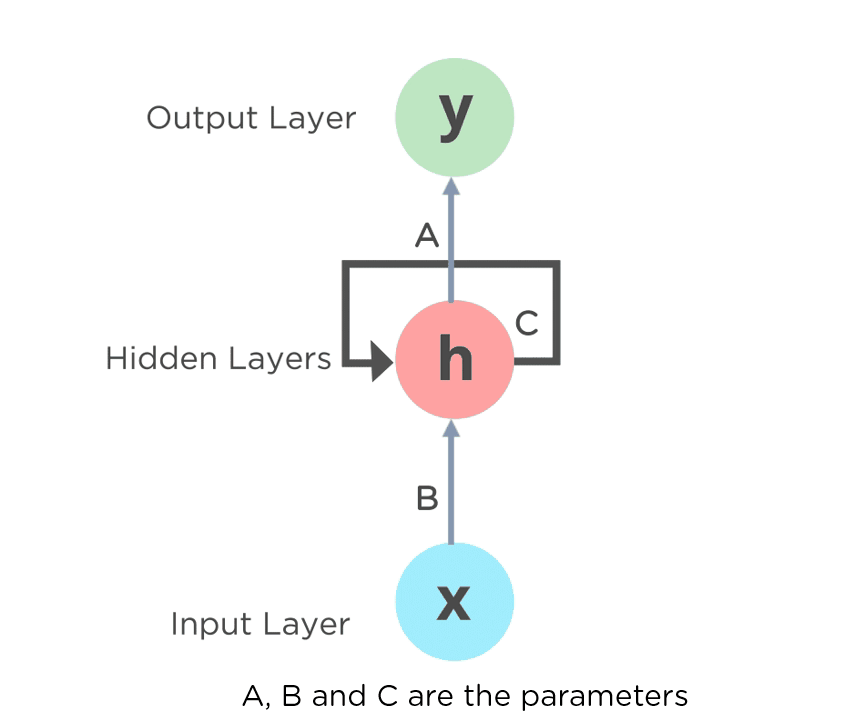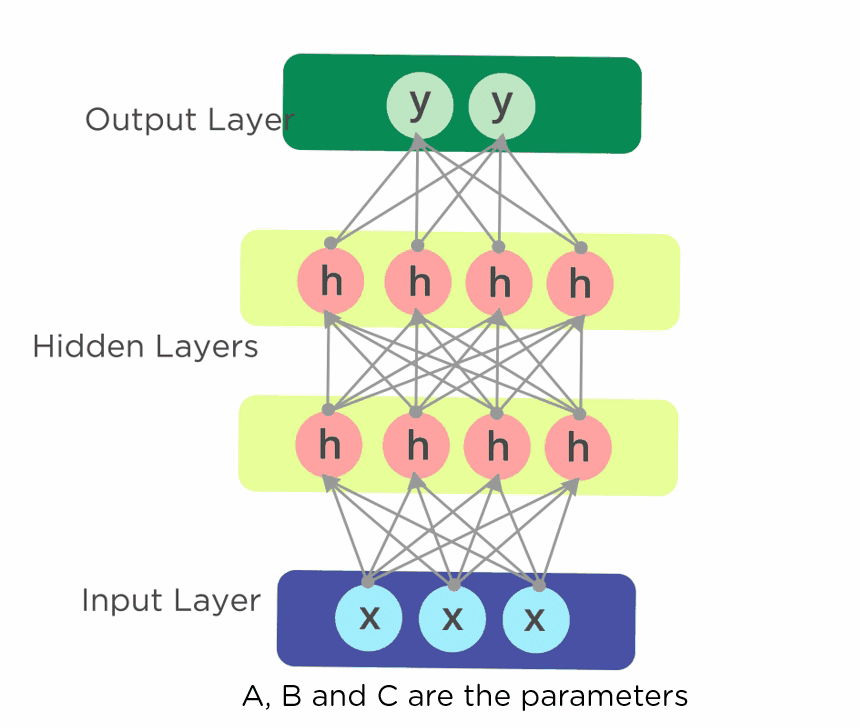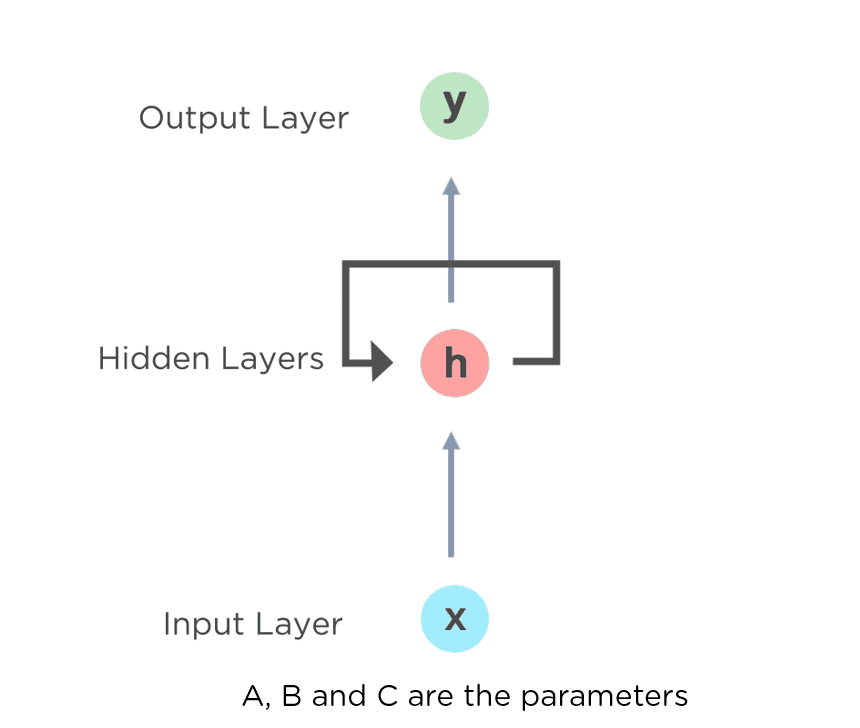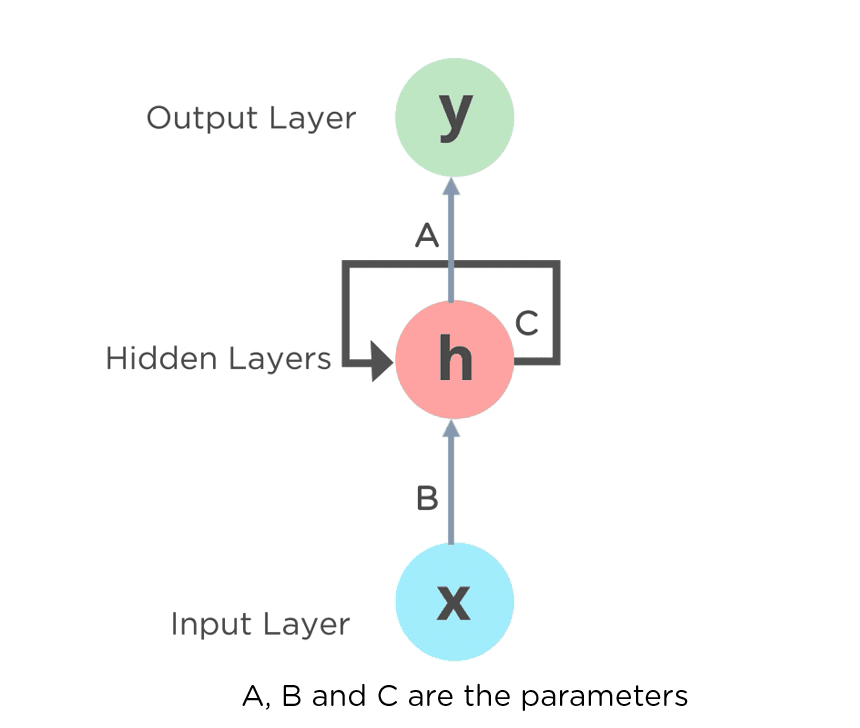
3. Neural Networks in Language Modeling
Recurrent Neural Network (RNN) Tutorial: Types and Examples [Updated] | Simplilearn
The introduction of neural networks in the late 1990s and early 2000s revolutionized various AI fields, including NLP. Neural language models, such as the Feed-Forward Neural Network Language Model and the Recurrent Neural Network Language Model, showcased improved performance in language processing tasks by learning complex representations of language.
RNN is a type of Neural Network where the output from the previous step is fed as input to the current step.
The main and most important feature of RNN is its Hidden state, which remembers some information about a sequence. The recurrent neural network in a deep learning model contains a feedback loop that predicts the output using the previous hidden state along the input.
RNNs were also susceptible to a plethora of issues:
- Vanishing and Exploding Gradients: One of the significant challenges with RNNs is the vanishing and exploding gradient problem. When training deep RNNs, the gradients can become too small or too large, making it challenging to update the model’s parameters effectively.
Gradients are like a magic tool that helps machines learn and get better at tasks. They show us how things change when we make little adjustments, just like figuring out how fast a toy car goes when we push it harder. Gradients make machines smarter by learning from their mistakes and improving their performance over time.
Limited Context: RNNs have a limited ability to capture long-term dependencies due to the vanishing gradient problem. Information from early time steps may not be retained for later steps in long sequences, hindering their ability to model long-range dependencies effectively.
Computational Efficiency: RNNs are inherently sequential models, making them computationally inefficient on parallel hardware like GPUs. Training large RNNs on extensive datasets can be time-consuming.
Despite their disadvantages, RNNs have been pivotal in the advancement of sequence modeling and have laid the groundwork for more sophisticated architectures like LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units), which address some of the vanishing gradient problems and extend the capabilities of RNNs.
4. Long Short-Term Memory (LSTM) Networks
Around 1997, the LSTM network architecture was proposed to address the vanishing and exploding gradient problem in RNNs. LSTM networks enabled the capture of longer-term dependencies in language, improving the coherence and contextuality of generated text.
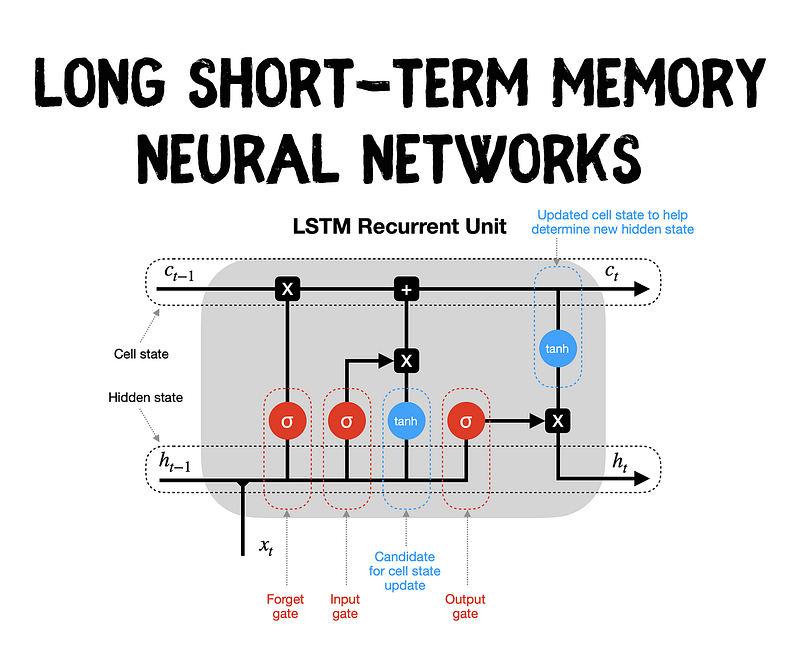
It overcame the vanishing gradient problem, which hindered the ability of RNNs to retain important information from earlier time steps in long sequences. LSTM’s unique architecture included a “memory cell” and “gates” that allowed it to selectively remember and forget information, making it highly effective for tasks involving sequences with long-term dependencies.
- Memory Cell and Gates: The core of LSTM is the memory cell, which can store information over long periods. It uses three types of gates — input gate, forget gate, and output gate — to control the flow of information and manage what should be remembered or discarded.
LSTM’s memory cell retains information*, allowing it to capture relevant context over long sequences. The **input gate decides what information to store in the memory cell*, while the *forget gate controls what to erase from the cell*. Finally, the *output gate decides which part of the memory cell to use as the output**.*
- Flexibility in Sequence Length: Unlike many other models, LSTM can process sequences of varying lengths, making it suitable for a wide range of tasks with variable-length inputs.
LSTM has indeed been a transformative advancement in RNNs, overcoming issues like the vanishing gradient problem and capturing long-range dependencies. However, it is not without its limitations. LSTM’s sequential nature can still lead to computational inefficiency and difficulty in parallelization. Additionally, while it can handle longer sequences better than traditional RNNs, it may still struggle with extremely lengthy inputs. This has spurred further research and the development of even more powerful models like attention mechanisms and transformers.
5. The Transformer Architecture
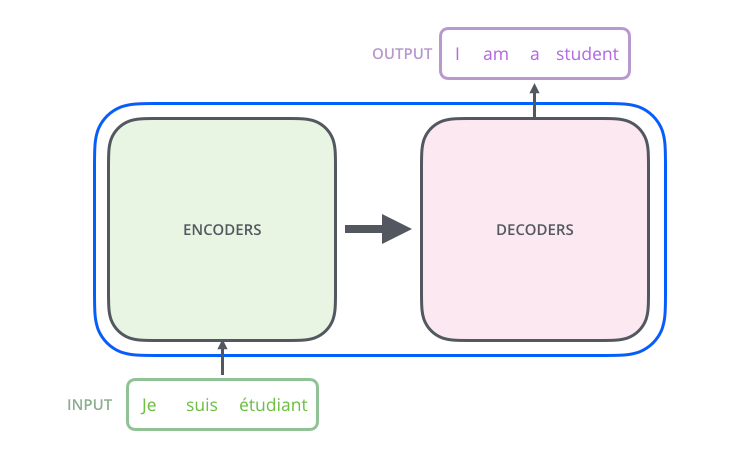
The Illustrated Transformer — Jay Alammar — Visualizing machine learning one concept at a time. (jalammar.github.io)
In December 2017, the groundbreaking “Attention is All You Need” paper introduced the Transformer architecture. This revolutionary architecture departed from the traditional sequential processing of data and instead focused on self-attention mechanisms. Unlike previous models like LSTM and RNNs, Transformers allowed the model to attend to all positions in the input sequence at once. This parallel processing capability enabled the model to efficiently capture long-range dependencies and significantly outperformed sequential models in various natural language processing tasks.
Attention is a key mechanism used in many machine learning models, particularly in the context of NLP and computer vision tasks. It allows the model to focus on specific parts of the input sequence or image that are most relevant to the task at hand. The idea behind attention is inspired by how human attention works, where we selectively concentrate on certain elements in a scene while ignoring others.
In NLP, the most commonly used attention mechanism is Self-Attention (also known as Scaled Dot-Product Attention). It is the foundation of the Transformer model and has revolutionized language modeling. Self-Attention enables a word in a sentence to attend to all other words in the same sentence, determining how much importance should be given to each word relative to the word being considered. This allows the model to capture long-range dependencies and better understand the context within the entire sentence.
In the case of language processing, attention mechanisms play a pivotal role in understanding and generating human-like text. Consider a sentence with several words; each word’s relevance to the overall meaning varies based on the context. With attention, the model can identify the most relevant words and assign them higher importance during the processing, making the model more context-aware.
Tokenization is a fundamental process in natural language processing that involves breaking down a piece of text, such as a sentence or a paragraph, into smaller units called tokens. In the context of language processing, tokens are typically words, subwords, or characters, depending on the level of granularity desired for the analysis.
The tokenization process is a crucial step before feeding text data into machine learning models or performing various NLP tasks. It converts raw text into a format that can be easily processed and analyzed by computers. Tokenization serves several purposes, such as reducing the computational complexity of text analysis, enabling numerical representation of words, and extracting meaningful information from the text.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI’s platform.platform.openai.com
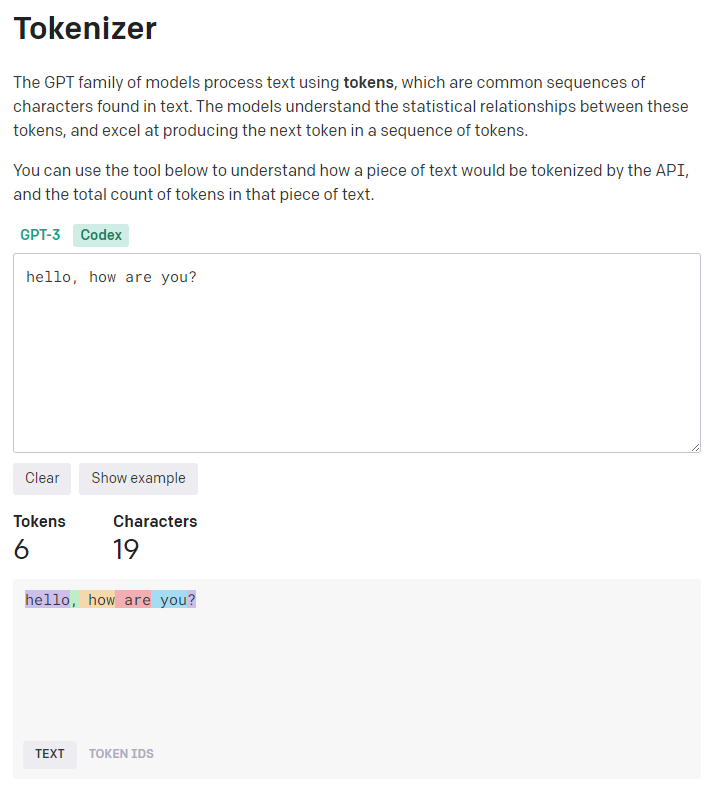
OpenAI’s Tokenizer: OpenAI Platform
There are different types of tokenization methods:
Word Tokenization: This is the most common type of tokenization, where the text is split into individual words. For example, the sentence “Hello, how are you?” would be tokenized into [“Hello”, “,”, “how”, “are”, “you”, “?”].
Subword Tokenization: In subword tokenization, words are further broken down into smaller subword units. This method is often used for languages with complex word formations or to handle out-of-vocabulary words. For instance, “unhappiness” might be tokenized into [“un”, “happi”, “ness”].
Character Tokenization: In character tokenization, each character in the text becomes a separate token. This level of granularity is useful for certain tasks like character-level language modeling.
Tokenization is the foundation of many NLP tasks, including language modeling, machine translation, sentiment analysis, and text classification. It helps models understand the structure of text and process it efficiently. Moreover, tokenization enables the conversion of text data into numerical representations, making it suitable for use in various machine learning algorithms and deep learning models.
Let’s walk through the tokenization process step-by-step using an example sentence and demonstrate the tokenized representation with code blocks. We will use different tokens, including special tokens like <start> and <stop> to indicate the beginning and end of the sentence, and <space> to represent spaces between words.
Example Sentence: “Hello, how are you?”
Step 1: Add Special Tokens:
Before tokenization, we add special tokens to indicate the beginning and end of the sentence. We will represent spaces as <space> for clarity.
Original Sentence: "Hello, how are you?"
Tokenized Sentence: "<start> Hello , <space> how <space> are <space> you ? <stop>"
Step 2: Word Tokenization:
Next, we tokenize the sentence into individual words.
Original Sentence: "Hello, how are you?"
Tokenized Sentence: "<start> Hello , <space> how <space> are <space> you ? <stop>"
Word Tokens: ["<start>", "Hello", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
Step 3: Subword Tokenization:
Now, let’s perform subword tokenization, breaking down words into smaller subword units using a hypothetical subword vocabulary.
Original Sentence: "Hello, how are you?"
Tokenized Sentence: "<start> Hello , <space> how <space> are <space> you ? <stop>"
Word Tokens: ["<start>", "Hello", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
Subword Tokens: ["<start>", "Hel", "lo", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
Step 4: Character Tokenization:
Finally, let’s tokenize the sentence at the character level.
Original Sentence: "Hello, how are you?"
Tokenized Sentence: "<start> Hello , <space> how <space> are <space> you ? <stop>"
Word Tokens: ["<start>", "Hello", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
Subword Tokens: ["<start>", "Hel", "lo", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
Character Tokens: ["<start>", "H", "e", "l", "l", "o", ",", "<space>", "h", "o", "w", "<space>", "a", "r", "e", "<space>", "y", "o", "u", "?", "<stop>"]
Tokenization allows us to represent the original sentence in a structured format, breaking it down into meaningful units that can be processed efficiently by machine learning models. Each level of tokenization provides different levels of granularity, offering flexibility for various NLP tasks and model architectures. The tokenized representation facilitates numerical encoding and further analysis for tasks like language modeling, machine translation, and sentiment analysis.
After tokenization, the main focus shifts to numerical encoding, which involves converting the tokenized text into numerical representations that machine learning models can understand. Numerical encoding is a crucial step as it enables the model to process and analyze the text using numerical operations, which are at the core of most machine learning algorithms.
Encoding in Transformers:
In transformers, encoding refers to the process of transforming the input text into contextualized word embeddings. The input text is tokenized into individual words or subwords, and each token is mapped to its corresponding word embedding. The transformer model processes these embeddings through a series of attention-based encoder layers. These layers enable the model to capture the relationships between words and their contextual significance in the entire sequence.
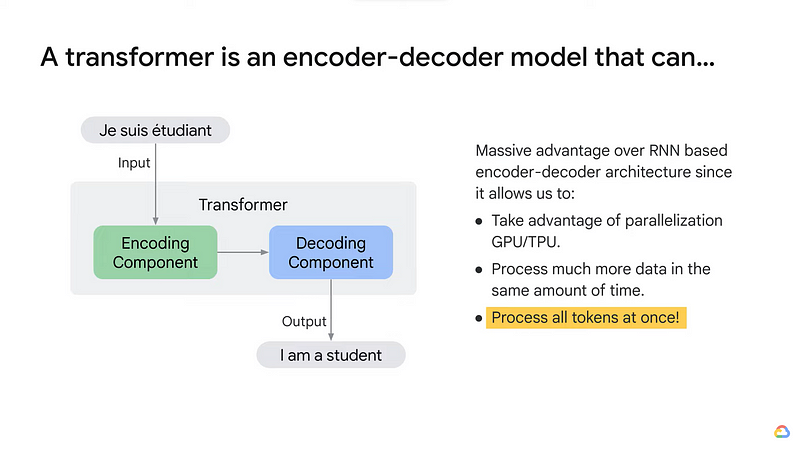
Transformer models and BERT model: Overview — YouTube
Example of Encoding in Transformers:
Consider the sentence: “The cat sat on the mat.”
Tokenization: The sentence is tokenized into individual words: [“The”, “cat”, “sat”, “on”, “the”, “mat”, “.”].
Word Embeddings: Each word is mapped to its corresponding word embedding:
Word Embeddings:
"The": [0.25, -0.17, 0.38, ...]
"cat": [0.73, 0.42, -0.29, ...]
"sat": [-0.15, 0.95, 0.06, ...]
"on": [0.11, -0.53, 0.27, ...]
"the": [0.25, -0.17, 0.38, ...] # Same embedding as "The" due to sharing
"mat": [-0.68, 0.09, 0.52, ...]
".": [0.37, -0.71, -0.08, ...]
- Encoding with Transformers: The transformer encoder processes these word embeddings through multiple layers of self-attention and feed-forward neural networks, capturing contextual information for each token in the sentence.
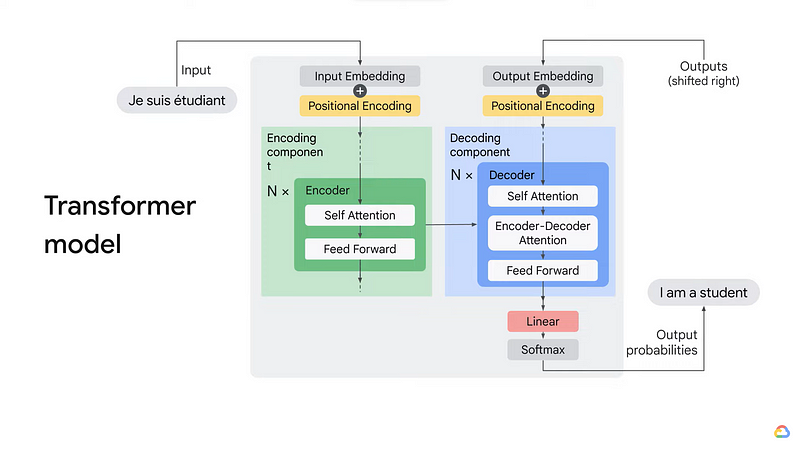
Transformer models and BERT model: Overview — YouTube
Numerical Encoding:

Tokenization in Machine Learning Explained (vaclavkosar.com)
In numerical encoding, each token in the tokenized sequence is mapped to a unique integer index, creating a vocabulary or dictionary. For example, the word “hello” might be mapped to index 23, while the word “how” might be mapped to index 45. This mapping allows the model to represent the input text as a sequence of integers, with each integer representing a specific word or token in the vocabulary.
In this example, we start with a tokenized sentence represented by the
tokenized_sentencelist. We then create avocabdictionary that maps each unique token to a unique index. Finally, we perform numerical encoding by using a list comprehension to replace each token in thetokenized_sentencewith its corresponding index from thevocabdictionary, resulting in theencoded_sentencelist.
# Sample tokenized sentence
tokenized_sentence = ["<start>", "Hello", ",", "<space>", "how", "<space>", "are", "<space>", "you", "?", "<stop>"]
# Create a vocabulary and map each token to a unique index
vocab = {"<start>": 0, "Hello": 1, ",": 2, "<space>": 3, "how": 4, "are": 5, "you": 6, "?": 7, "<stop>": 8}
# Numerical encoding using the vocabulary
encoded_sentence = [vocab[token] for token in tokenized_sentence]
print("Tokenized Sentence:", tokenized_sentence)
print("Encoded Sentence:", encoded_sentence)
Output:
Tokenized Sentence: ['<start>', 'Hello', ',', '<space>', 'how', '<space>', 'are', '<space>', 'you', '?', '<stop>']
Encoded Sentence: [0, 1, 2, 3, 4, 3, 5, 3, 6, 7, 8]
Numerical encoding is a necessary step to feed the tokenized text into neural networks, where computations are performed on numerical data. Additionally, numerical representations enable the use of word embeddings, which are dense vector representations that capture the semantic meaning and relationships between words. Word embeddings provide a more meaningful and continuous representation of words, allowing the model to learn contextual information and generalize better to unseen data.
In this blog, we will delve deeper into word embeddings and how they are used to represent tokens as dense vectors in vector databases. These embeddings play a crucial role in various language tasks and help models understand the underlying meaning and context of words in the text.
Decoding in Transformers:

Transformer: A Novel Neural Network Architecture for Language Understanding — Google Research Blog (googleblog.com)
In transformers, decoding is the process of generating the output sequence, which could be the next word in language modeling or the translated sentence in machine translation tasks. Transformers employ an attention-based decoder to generate the output sequence based on the encoded input and previous predictions.
Example of Decoding in Transformers:
Assuming we are performing language modeling and want to predict the next word after “The cat sat on the”, the transformer decoder takes the encoded representation of the input text (“The cat sat on the mat.”) and generates the next word based on the context and learned patterns from the training data.
For example, the transformer may predict that the next word is “floor”, resulting in the completion: “The cat sat on the floor.”
Both encoding and decoding are iterative processes in transformers. During encoding, the model updates the embeddings and captures contextual information layer by layer. In decoding, the model generates the output tokens one by one based on the context and previously generated tokens.
Transformers’ ability to handle long-range dependencies and capture contextual information has led to significant improvements in various NLP tasks, including machine translation, text generation, sentiment analysis, and more. Their success lies in effectively encoding and decoding text data, making them one of the most powerful architectures in the field of natural language processing.
Let’s take a more detailed example of translating an English sentence into Hindi using an attention-based machine translation model:
English Input Sentence: “The sun is shining.”
1. Tokenization:
The input sentence is tokenized into individual words: [“The”, “sun”, “is”, “shining”, “.”].
- Translation Model Initialization:
The translation model starts with an initial state and attention weights initialized to equal importance for all words in the input sentence.
3. Word Embeddings:
Next, we map each word in the tokenized English sentence to its corresponding word embedding:
Word Embeddings:
"The": [0.25, -0.17, 0.38, ...]
"sun": [-0.68, 0.09, 0.52, ...]
"is": [-0.15, 0.95, 0.06, ...]
"shining": [0.11, -0.53, 0.27, ...]
".": [0.37, -0.71, -0.08, ...]
4. Transformer Encoding:
The transformer model processes these word embeddings through multiple encoder layers to capture contextual information.
5. Decoding to Hindi:
During decoding, the transformer model generates the output tokens one by one, based on the context and previously generated tokens. For simplicity, let’s assume the transformer predicts the next word to be “चमक रहा है” (pronounced as “chamak raha hai”), which means “is shining” in Hindi.
6. Contextual Adaptation:
As the model proceeds through the translation process, the attention weights continuously adapt based on the context and the words generated so far in the output sequence.
7. Output: The translation model produces the final Hindi translation: “सूरज चमक रहा है।”
The transformer-based translation leverages its understanding of the context and relationships between words to generate accurate and contextually appropriate translations. This approach has proven to be highly effective in machine translation tasks, enabling the model to produce high-quality translations between different languages.
6. GPT and BERT
In 2018, OpenAI’s “GPT” (Generative Pre-trained Transformer) and Google’s “BERT” (Bidirectional Encoder Representations from Transformers) were introduced, further advancing the capabilities of LLMs. GPT demonstrated the power of large-scale pre-training followed by fine-tuning on specific tasks, while BERT introduced bidirectional context understanding, significantly improving language understanding and context-based predictions.
Pre-Training LLMs
Pre-training refers to the initial phase of training a language model on a large corpus of text data without any specific task in mind. During pre-training, the model learns to predict missing words in sentences or other related tasks using self-supervised learning techniques.
Self-supervised learning is like solving word puzzles. A computer learns from a bunch of sentences with some words missing. It figures out the missing words by looking at the other words around them. By playing this word puzzle game a lot, the computer gets really good at understanding language and can help with writing, answering questions, and more!
For example, in the “masked language modeling” task, certain words in the input sentences are randomly masked, and the model is trained to predict the masked words based on the context of the surrounding words. The goal is for the model to learn the underlying structure and grammar of the language, as well as capture meaningful relationships between words and context.

Transformer models and BERT model: Overview — YouTube
Pre-training is crucial because it enables the model to learn a general understanding of language patterns from diverse data sources, acquiring broad knowledge about grammar, semantics, and syntax. Pre-trained models like GPT and BERT, having learned from vast amounts of text, can then be fine-tuned for specific tasks with relatively smaller labeled datasets.
Fine-Tuning LLMs
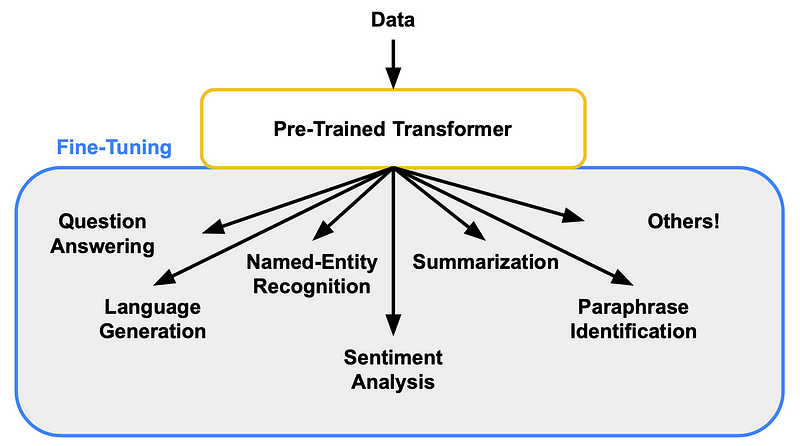
Fine-Tuning Transformers for NLP (assemblyai.com)
Fine-tuning, also known as transfer learning, is the subsequent phase after pre-training. In fine-tuning, the pre-trained language model is further trained on specific downstream tasks that require labeled datasets. These tasks can include text classification, sentiment analysis, question answering, named entity recognition, and more.
Instead of starting from scratch, fine-tuning leverages the knowledge learned during pre-training and adapts it to the particular task at hand. Fine-tuning is achieved by updating the model’s parameters using the labeled task-specific data, which fine-tunes the model’s understanding of the specific domain or task.
Fine-tuning is essential because it allows pre-trained models to be specialized for specific tasks, making them capable of achieving high performance on a wide range of NLP tasks without the need for massive task-specific datasets. The combination of pre-training and fine-tuning has significantly advanced the capabilities of large language models, making them powerful and adaptable tools for various natural language processing tasks.
Training GPT
The training process of GPT is a multi-step procedure that involves pre-training and fine-tuning. Let’s delve into the detailed training process of GPT:
Pre-training:
Dataset Collection: The first step is to collect a large corpus of raw text data from various sources, such as books, articles, websites, and more. The more diverse and extensive the dataset, the better GPT can learn the nuances of language.
Tokenization: The raw text data is tokenized into smaller units, such as words or subwords, to create a vocabulary. Each token is assigned a unique integer index.
Masked Language Modeling: GPT uses a self-supervised learning technique called masked language modeling. During this phase, a percentage of the tokens in the input sentences are randomly masked, and the model’s objective is to predict the masked tokens based on the context provided by the surrounding tokens.
Architecture of GPT: GPT is based on the transformer architecture, which consists of multiple layers of self-attention and feed-forward neural networks. The model uses a stack of transformer decoder layers, making it a “decoder-only” architecture.
Learning Context and Relationships: Through the masked language modeling task, GPT learns to understand the context and relationships between words, acquiring knowledge about grammar, syntax, and semantics.
Unsupervised Pre-training: The model is trained on the large corpus of text data without any specific task supervision. It learns to predict the masked tokens by iteratively adjusting its parameters to minimize prediction errors.
Iterative Training: The pre-training process is repeated for multiple epochs to allow the model to learn from the data and refine its understanding of language.
Imagine you are playing a game, and each time you finish a level, you start again from the beginning. An epoch is like completing one full round of the game. So, if you play the game three times, you have completed three epochs. It helps the computer learn more about the game and get better at playing it!
Fine-tuning:
Task-Specific Datasets: After pre-training, GPT is fine-tuned on specific downstream tasks that require labeled datasets, such as text classification, sentiment analysis, or question answering.
Training with Labeled Data: For fine-tuning, GPT uses the task-specific labeled datasets. The model’s parameters are updated during fine-tuning to adapt its knowledge to the specific task.
Transfer Learning: Fine-tuning leverages the language understanding learned during pre-training and tailors it to the target task, making GPT highly effective in various NLP tasks.
Iterative Fine-tuning: Similar to pre-training, fine-tuning can be performed for multiple epochs to improve the model’s performance on the specific task.
By combining pre-training with fine-tuning, GPT becomes a powerful language model capable of understanding and generating human-like text, making it a valuable tool for a wide range of natural language processing applications.
7. Scaling to GPT-3:
The introduction of “GPT-3” by OpenAI in 2020 marked a significant milestone in the evolution of LLMs. With a whopping 175 billion parameters, GPT-3 became the largest and most powerful language model at that time, showcasing remarkable language generation, translation, and problem-solving capabilities.
8. Google’s PaLM (Pathways Language Model) and PaLM2

PALM and PALM2 are LLMs developed by Google AI. They are based on the transformer architecture and are trained on a massive dataset of text and code. PALM has 537 billion parameters, while PALM2 has 1.37 trillion parameters. This makes them some of the most powerful LLMs ever created.
PALM and PALM2 have achieved state-of-the-art results on a variety of natural language processing tasks, including question answering, summarization, and translation. They are supposedly more efficient to train than previous LLMs, making them more accessible to researchers and developers. Additionally, they are supposedly less prone to bias than previous LLMs, making them a more reliable tool for natural language processing tasks.
The development of PALM and PALM2 represents a significant advancement in the state of the art in LLMs. These models are more powerful, efficient, and less biased than previous LLMs, making them a valuable tool for a wide range of applications.
The key achievements of PALM and PALM2 include:
State-of-the-art results on a variety of natural language processing tasks: PALM and PALM2 have achieved state-of-the-art results on a variety of natural language processing tasks, including question answering, summarization, and translation. For example, PALM achieved a score of 94.9 on the SQuAD question answering benchmark, which is the highest score ever reported.
Efficiency: PALM and PALM2 are more efficient to train than previous LLMs. This makes them more accessible to researchers and developers, who can now train these models on a single GPU.
Bias: PALM and PALM2 are less prone to bias than previous LLMs. This makes them a more reliable tool for natural language processing tasks, as they are less likely to generate text that is biased or offensive.
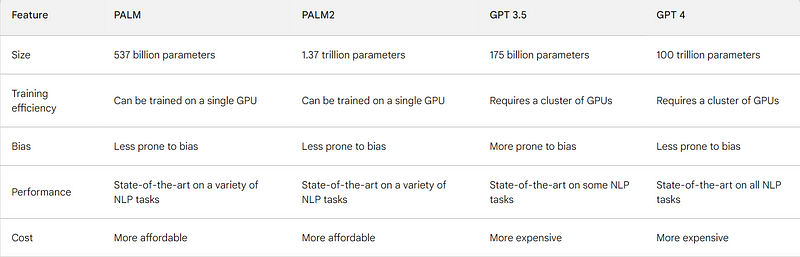
Differences between PaLM, PaLM2, GPT 3.5 and GPT 4
Applications of LLMs
Let’s now focus on the application of LLMs, especially their application in Image Generation:
While LLMs are primarily known for their language-related applications, they have also been adapted for image generation tasks. LLMs can be fine-tuned to generate realistic and contextually relevant images based on textual descriptions or prompts. This remarkable capability has opened up new possibilities in the field of image synthesis and creative content generation.
Text-to-Image Synthesis:
LLMs have been integrated with advanced image generation models to create what is known as text-to-image synthesis. Given a textual description as input, the LLM can understand the context and generate high-quality images that match the provided description. For example, given the prompt “a sunny beach with palm trees,” the LLM-powered image generation model can produce a beautiful beach scene with palm trees, all based on its understanding of language and visual concepts.

a sunny beach with palm trees — Image Creator from Microsoft Bing
Style Transfer:
LLMs have also been employed in style transfer tasks, where they can transform images according to a given style described in text. For example, an LLM can be used to apply artistic styles, like “painting in the style of Van Gogh,” to input images, effectively transferring the desired style to the generated images.

a sunny beach with palm trees in the style of vincent van gogh — Image Creator from Microsoft Bing
Image Captioning:
LLMs can be utilized for image captioning tasks as well. Given an input image, the LLM can generate descriptive and contextually relevant captions that accurately describe the content of the image.
Image captions - Image Analysis 4.0 - Azure AI services
Concepts related to the image captioning feature of the Image Analysis 4.0 API.learn.microsoft.com
Image Generation using Diffusion:
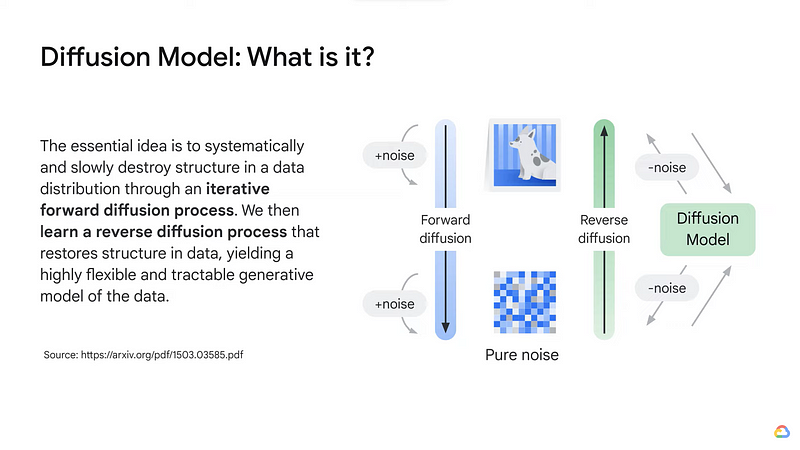
Introduction to image generation — YouTube
Diffusion models are a type of generative model that can be used to generate images, text, and other creative content. They work by starting with a random noise image or text and then gradually adding detail to the image or text until it resembles the desired output.
The process of adding detail is called diffusion, and it is based on the idea that natural images and text can be represented as a collection of random noise that has been gradually smoothed out. Diffusion models learn to perform this smoothing process by being trained on a dataset of real images or text.
One of the advantages of diffusion models is that they are relatively simple to train. This is because they do not require as much data as other types of generative models, such as GANs. Diffusion models can also be used to generate images and text that are more realistic and creative than those that can be generated by other methods.
However, diffusion models also have some limitations. One limitation is that they can be slow to generate images and text. This is because they need to gradually add detail to the image or text, which can take a long time. Another limitation is that diffusion models can sometimes generate images and text that are blurry or unrealistic.
Overall, diffusion models are a powerful tool for generating images and text. They are relatively simple to train and can generate images and text that are more realistic and creative than those that can be generated by other methods. However, they can be slow to generate images and text, and they can sometimes generate images and text that are blurry or unrealistic.
GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - Stability-AI/stablediffusion: High-Resolution…github.com
How Vector Databases Help with Images and Search Engines
A video explaining what Vector Databases are
These days image search engines have become an essential part of our daily lives. These engines allow us to find relevant images quickly and efficiently. Behind the scenes, one of the critical components enabling this efficiency is the use of Vector Databases. These databases employ advanced techniques to represent images as vectors in high-dimensional spaces, making image retrieval and search processes faster and more accurate than ever before.
Vector databases are so hot right now. WTF are they? — YouTube
Vectors are mathematical objects that represent points in a high-dimensional space. The dimensions of the space represent different features of the data, such as the color of an image or the words in a text document.
Vector databases are well-suited for storing image data because they can be used to represent the visual features of images. This allows vector databases to be used for tasks such as image search and retrieval. For example, a vector database could be used to find all images that contain a particular object or scene.
Vector databases can also be used for text search. This is because the vectors that represent text documents can be compared to each other to determine how similar they are. This allows vector databases to be used to find documents that are related to a particular topic.
Vector Representation of Images
Vector databases use sophisticated algorithms to convert images into numerical vectors. Each vector represents a unique combination of image features, such as colors, textures, shapes, and patterns. These high-dimensional vectors allow images to be efficiently indexed and compared based on their similarity.
Enhancing Image Retrieval
Traditional image search engines often rely on textual metadata or tags associated with images, which can be limited and imprecise. In contrast, vector databases consider the inherent visual content of images. By comparing vectors, these databases can retrieve visually similar images, even if they are not explicitly tagged with similar keywords. This capability significantly improves the relevance and accuracy of image search results.
Efficiency and Speed
Vector databases use advanced data structures and indexing techniques to store and retrieve images efficiently. Searching through vast collections of images becomes faster, as the search engine can quickly narrow down the pool of potential matches based on vector similarity. This results in a more responsive and user-friendly image search experience.
Applications Beyond Images
Beyond image search engines, vector databases find applications in various fields, such as natural language processing and recommendation systems. For example, in NLP, word embeddings are used to represent words as vectors, enabling more effective semantic analysis and language understanding.
The Shortcomings of Vector Databases
Like any technology, vector databases come with their own set of drawbacks.
Complexity: Setting up and managing vector databases can be more complex compared to traditional relational databases. Fine-tuning the index structure often demands careful parameter adjustments to ensure optimal performance.
Limited Transactional Workloads Support: While vector databases excel in analytics and search tasks, they are not specifically designed to handle transactional workloads, which are commonly required in various business applications. As a result, other database solutions might be more suitable for transaction-oriented use cases.
Ethical Considerations: The Negative Effects of LLMs

LLMs have made remarkable strides in natural language processing, but they also pose ethical concerns. The extensive language generation capabilities of LLMs come with potential negative effects, including bias amplification, misinformation spread, offensive language, and even hallucinations, leading to unintended consequences in the information landscape.
Amplification of Bias: LLMs trained on biased data can perpetuate societal biases, reinforcing stereotypes and marginalizing certain groups unintentionally.
Misinformation and Disinformation: LLMs can inadvertently generate false or misleading information, leading to the spread of disinformation and fake news.
Unintended Offensive Language: In their text generation, LLMs may unintentionally include offensive or harmful language, impacting users negatively.
Hallucinations: LLMs can “hallucinate” information not present in the training data, generating seemingly realistic but completely fictional content.
Over-Reliance on Automated Content: Relying heavily on LLM-generated content without proper verification may lead to the dissemination of unverified or poorly fact-checked information.
Privacy Concerns: LLMs may inadvertently reproduce private or sensitive information, raising privacy concerns.
Conclusion
LLMs have emerged as revolutionary tools in the field of NLP and beyond. Their ability to understand and generate human-like text has transformed various applications, from machine translation and sentiment analysis to chatbots and virtual assistants. LLMs, such as GPT and BERT, have showcased the power of pre-training and fine-tuning in capturing language patterns and context, leading to significant advancements in NLP tasks.
Moreover, the evolution of LLMs has paved the way for attention mechanisms and transformer architectures, which have become fundamental building blocks in the realm of deep learning. With applications spanning image generation, diffusion models have brought a new level of creativity to computer-generated visuals.
The use of LLMs has not been without challenges, including ethical considerations such as bias and misinformation. However, ongoing research and efforts are dedicated to addressing these limitations and promoting responsible use.
As we look to the future, the potential of LLMs seems boundless. They continue to shape the way we interact with language, images, and information, and their applications are expanding across diverse fields. LLMs hold the promise of enhancing human-machine interactions and driving innovation in artificial intelligence.
To fully grasp the significance of LLMs and their impact, I encourage readers to delve deeper into this fascinating domain. Exploring research papers, articles, and online resources on LLMs will provide invaluable insights into their architecture, applications, and ongoing advancements.
To learn more about me and discover additional insights on web development, cloud computing, and serverless architectures, visit vaishnav.tech. You can also explore my Medium articles by visiting wishee.medium.com for more in-depth content or connect with me on Twitter @ twitter.com/vaishnav_mk1